😁 Hello, super humans! Three days after launch, two of the most capable models on the planet went dark — not because of a bug or a jailbreak, but because of an executive order. If your weekend plans involved building on a frontier model, this week is a reminder that your AI stack can disappear overnight. Let’s dig in.
📰 Quick Signals
- 🧠 AI: A 42-state coalition led by New York AG Letitia James subpoenaed OpenAI over its ads, engagement design, data handling, and chatbot “sycophancy,” days after its near-$1T IPO filing (Bloomberg).
- 🤖 Robotics: NEURA Robotics raised up to $1.4B in Series C for physical AI, backed by Nvidia, Amazon, Qualcomm, Tether, Bosch and Schaeffler (The Robot Report).
- 💻 Programming: At WWDC, Apple made its Foundation Models free on Private Cloud Compute for smaller developers, removing the infrastructure bill from shipping AI features (MacRumors).
- ⚡ Electronics: SK Hynix detailed a 16-layer, 48GB HBM4 stack pushing past 2 TB/s of bandwidth, as the memory makers start sampling HBM4 to Nvidia (EE Times).
- 📡 Telecom: The NTIA launched spectrum.gov to track the U.S. 6G pipeline and spectrum-sharing work ahead of WRC-2027 (Light Reading).
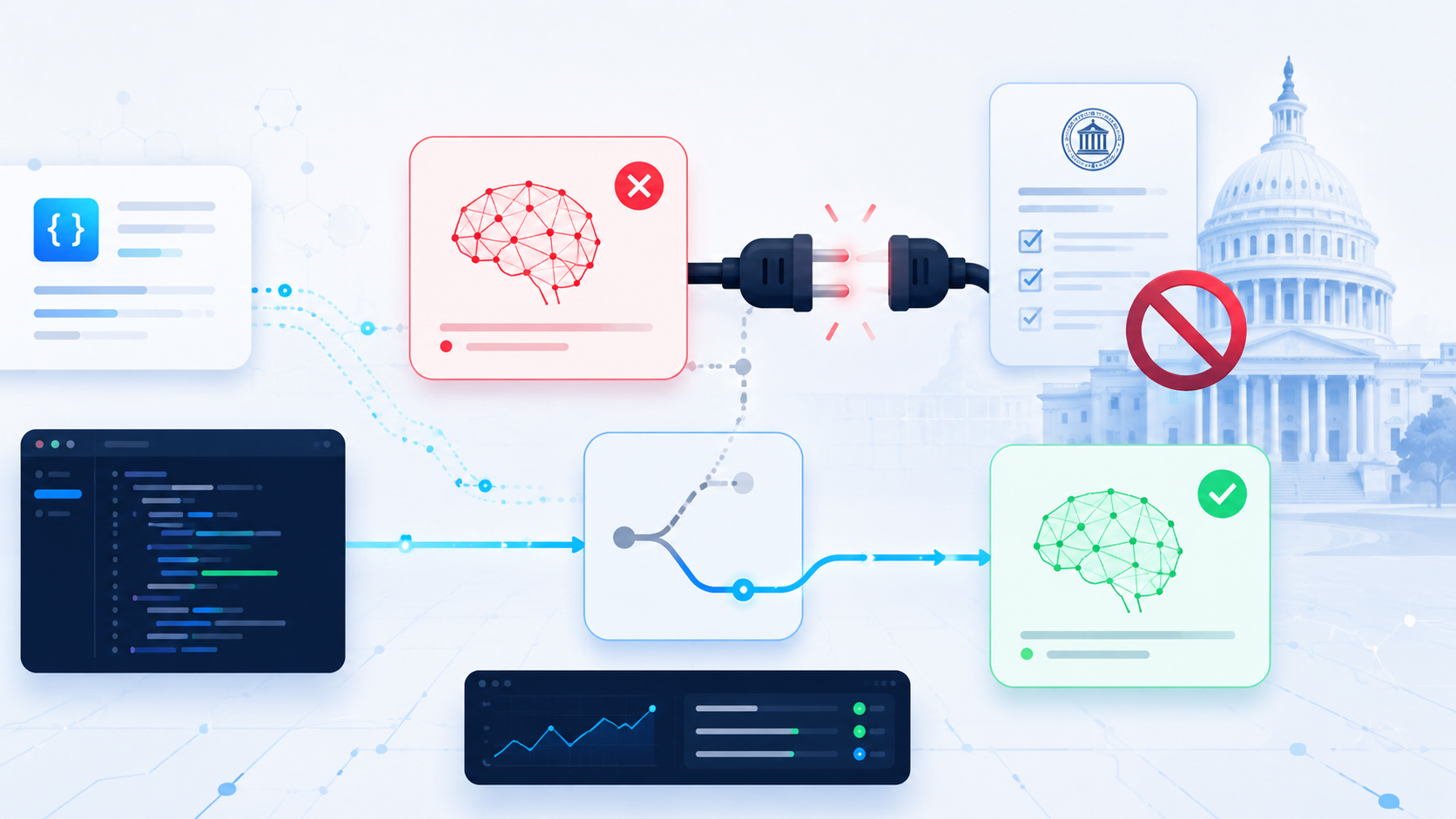
The Big Story: A frontier model just got government-yanked mid-deployment
For the first time ever, a government reached in and switched off a frontier AI model that was already live. Not throttled, not fined — switched off. If you build on third-party models, this is the most important risk event of the year so far.
What happened: The U.S. government used national-security export-control powers to issue a directive targeting two of Anthropic’s newest models, Fable 5 and Mythos 5. Export controls restrict who can access a technology; this order blocks any foreign national from using the two models, including Anthropic’s own foreign-national employees. Because there’s no clean way to verify citizenship at the API layer, Anthropic’s only safe move was a full cutoff: Fable 5 and Mythos 5 are disabled for everyone, worldwide, three days after launch. All other Claude models keep working normally. Over the weekend Anthropic sent senior staff, including co-founder Tom Brown, to Washington to negotiate restoring access directly with the White House (BeInCrypto).
The details: This is a different failure mode than the outages you plan for. There’s no status page to refresh, and no retry that fixes it. The model is gone by legal instruction, not infrastructure failure. Anthropic calls it a misunderstanding and says it’s working to reverse it, but the precedent is the story: a model you depend on can be pulled by executive action between one deploy and the next, with no notice and no per-user carve-out. The “swap them out now” guidance from Anthropic is the tell: if your product hard-codes a single model name, you just learned your provider’s legal exposure is now your uptime problem.
Important
Our take: Treat model choice like any other single point of failure — abstract it. The teams that shrugged this off had a provider-agnostic gateway and a fallback model behind a feature flag; the teams that paled had model="fable-5" hard-coded in forty places. You don’t need five providers in production, you need the ability to switch to one in an afternoon. Diversify your providers, keep an open-weights option you can self-host, and write your code so the model name is config, never a constant. Geopolitics is now part of your dependency graph.
🗞️ More News
A fuller roundup across the beat — AI runs deep this week, with the rest of the verticals close behind.
🧠 AI
- Moonshot AI open-sourced Kimi-K2.7-Code, a 1T-parameter MoE (32B active, 256K context) that uses ~30% fewer reasoning tokens while gaining +21.8% on Kimi Code Bench v2 (Hugging Face).
- Z.ai shipped GLM-5.2, a coding model with a 1M-token context window, with open weights under MIT promised next week (Z.ai).
- Google DeepMind published a paper mapping four concrete paths from human-level AGI to superintelligence, scaling, new paradigms, recursive self-improvement, and massive multi-agent systems (arXiv).
- LMCache released an open-source KV-cache layer that claims up to 10x faster LLM inference by reusing computed context across requests (GitHub).
- Unsloth shipped quantized MiniMax M3, bringing the multimodal model to local rigs with GGUF support (Unsloth).
- Google’s new text-to-SQL model topped the BIRD benchmark with execution-ready queries, not just plausible-looking SQL (BIRD benchmark).
- Satya Nadella argued the real AI moat isn’t the model; it’s the “token capital” companies accumulate by feeding their own data and results back into the system over time (Digg).
- Google researchers are building a 2,000-phone datacenter out of retired Pixels, launching this fall to cut the carbon cost of new servers (Google Research).
🤖 Robotics
- Standard Bots raised $200M in Series C at a $1B valuation to expand U.S. manufacturing of its robotic arms in New York (The Robot Report).
- Allen Control Systems raised $200M in Series B at a $2.2B valuation to scale its autonomous counter-drone weapon station, Bullfrog (The Robot Report).
- Robotics startups have now raised $55.8B in 2026, nearly double last year’s record, per Dealroom data (The Robot Report).
- The Humanoid Robot Forum (June 23–24) will center on the hard question: What’s actually required to put humanoids to work safely at scale (A3).
💻 Programming
- Apple’s new Core AI framework lets developers run custom on-device models with ahead-of-time compilation and Python tools to convert PyTorch models to Apple silicon (MacRumors).
- OpenAI added a “developer mode” to Codex that exposes console logs, network calls, and page state inside Codex’s browser while you debug web apps (OpenAI).
- Cohere released North Mini Code, an open coding model small enough to run on a single high-end GPU for terminal tasks and code review (Cohere).
- Opik turns failed agent traces into root-cause reports, proposed fixes, and permanent regression tests so your agent harness gets harder to break over time (GitHub).
⚡ Electronics
- JEDEC finalized the HBM4 standard up to 2 TB/s over a 2048-bit interface, with new power-efficiency provisions for AI accelerators (EDN).
- Samsung says customers have praised its HBM4 competitiveness, “Samsung is back,” as it fights SK Hynix and Micron for the Nvidia supply slot (Reuters/Investing.com).
- Cortus CEO Michael Chapman laid out how RISC-V and AI could reshape Europe’s semiconductor future (eeNews Europe).
- China’s Xiangshan is now billed as the most powerful open-source RISC-V core in the world, as Beijing pushes a full domestic RISC-V ecosystem (China Daily).
📡 Telecom
- 6G research is pivoting away from sub-terahertz toward the FR3 (cmWave) band, which keeps realistic coverage from existing macro sites while adding bandwidth (Blackbox).
- Nokia and Ericsson deepened their cooperation on Autonomous Networks, with Ericsson joining Nokia’s open SMO Marketplace for multivendor automation apps (Ericsson).
- Nokia mapped its AI-RAN roadmap, targeting first commercial trials in 2026 and a commercial release in 2027 (DCD).
- Even as they push AI into the network, Ericsson and Nokia warn AI is making telecom more expensive, not cheaper, in the near term (Light Reading).
👨💻 Code Corner
The Big Story has a one-line fix: never call a model by name in your business logic. Here’s a tiny provider-failover wrapper. It tries models in priority order and falls through to the next the moment one is unavailable (a 4xx export-control block, a 5xx, a timeout). Swap the stubbed call_model for your real client calls:
import time
PROVIDERS = [
{"name": "fable-5", "client": "anthropic"}, # primary
{"name": "gpt-5.5", "client": "openai"}, # fallback
{"name": "glm-5.2", "client": "zai"}, # open-weights, self-hostable
]
class ModelUnavailable(Exception):
pass
def call_model(model: str, prompt: str) -> str:
"""Stand-in for a real client call. Raise ModelUnavailable to trigger failover."""
if model == "fable-5":
raise ModelUnavailable("403: blocked by export-control directive")
return f"[{model}] answered: {prompt[:40]}..."
def ask(prompt: str, providers=PROVIDERS, retries: int = 2) -> str:
for p in providers:
for attempt in range(1, retries + 1):
try:
return call_model(p["name"], prompt)
except ModelUnavailable as e:
print(f"[failover] {p['name']} down ({e}) — trying next provider")
break # don't retry a legal block; move on
except Exception as e:
print(f"[retry] {p['name']} attempt {attempt} failed: {e}")
time.sleep(0.5 * attempt)
raise RuntimeError("all providers exhausted")
print(ask("summarize today's newsletter"))Tip
Make the provider list config, not code — an env var or a small YAML file — so swapping your primary model is a one-line deploy, not a pull request. A legal block won’t fix itself on retry, so failover should move to the next provider immediately rather than burning attempts on the dead one.
🧰 Toolbox
- OpenRouter Model Fusion — sends one prompt to several models, checks where they agree, and blends the best answers; pairs well with this week’s “diversify your providers” lesson.
- LMCache — open-source KV-cache layer that reuses computed context to cut inference latency by up to 10x.
- Kimi Code — terminal coding agent powered by Moonshot’s new K2.7-Code, tuned for long-horizon work with fewer wasted tokens.
- Headroom — compresses tool outputs, logs, and retrieval chunks before they hit your model, trimming token usage 60–95%.
- Omnigent — runs a coding or knowledge-work agent on your laptop, then lets you resume the same live session from your phone or a browser.
- Knowledge Graph Extractor — turns documents, URLs, or zip files into an interactive map of connected facts.
🛠️ Build of the Week (rotating)
Provider-failover LLM gateway: a thin local service that fronts every model call in your app, picks a provider from a config list, and transparently fails over when your primary goes darkexactly the muscle the Big Story says you need.
- Difficulty: Intermediate
- Parts: the failover wrapper above, an env-var or YAML provider list, two or more provider API keys, one self-hostable open-weights model (e.g. GLM-5.2) as the last-resort tier, basic logging
- Why we like it: it converts “our model got export-controlled” from a business-ending outage into a one-line config change — and you build it once, before you need it.
😀 The Bot Says…
We finally have an AI that can’t be jailbroken, can’t be prompt-injected, and can’t be misused. It’s also the one the government turned off. 🔌🇺🇸
That’s all for today! Is your stack one executive order away from a bad week — or do you have a fallback model behind a flag? Reply and tell us how you’d hot-swap a provider.
Forwarded this by a friend? Subscribe here to get the next issue in your inbox.


